When your favorite app, streaming platform, or internet provider goes down, you need answers fast. That’s why we are excited to introduce a modern refresh to the Downdetector web experience, designed to bring new features and significantly upgrade your user experience. This redesign brings Downdetector into a new era, creating a flexible, accessible framework that paves the way for more future enhancements.
What’s New in the Downdetector Refresh
We’ve rebuilt the Downdetector web experience to give you more clarity and control when troubleshooting your digital world. Here are some key features to look out for:
Enhanced UI: Enjoy a sleek, modernized interface with improved accessibility across both mobile and desktop platforms. Navigating outage data is now even smoother and more intuitive, no matter what device you are using.
Improved Service Indicators: Get the answers you need at a glance. We’ve updated our service indicators to provide clearer, immediate visual cues of which services are actively experiencing problems.
Enhanced Search with Trending Services: Find what you’re looking for instantly. Our upgraded search feature now highlights trending services so you can jump straight to platforms experiencing active outages.
Light and Dark Mode Support: You can now easily toggle between Light Mode and Dark Mode to match your system preferences and reduce eye strain during those late-night service disruptions.
Multi-Language Support: To better serve our global community, the new web experience is tailored to your location. Depending on your region, the site now supports the primary local languages, in addition to English.
Now Available Globally
The rollout is complete! The refreshed Downdetector web experience is now live across all 67 countries we serve. You can explore the newly upgraded design in the following locations:
The Americas: Brazil, Canada, Chile, Colombia, Costa Rica, Dominican Republic, Ecuador, Guatemala, Mexico, Panama, Perú, Puerto Rico, and the USA.
Europe: Azerbaijan, Belgium, Bulgaria, Croatia, Czech Republic, Denmark, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Netherlands, Norway, Poland, Portugal, Romania, Serbia, Slovakia, Spain, Sweden, Switzerland, Turkey, Ukraine, and the UK.
Middle East & Africa: Algeria, Israel, Jordan, Kenya, Morocco, Nigeria, South Africa, Tunisia, and the UAE.
Asia-Pacific: Australia, Bangladesh, Hong Kong, India, Indonesia, Japan, Malaysia, New Zealand, Pakistan, Philippines, Singapore, Taiwan, Thailand, and Vietnam.
Visit Downdetector today to check out the new look and monitor outages in your region!
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Ookla® is a global leader in connectivity intelligence that provides consumers, businesses, and other organizations with data-driven insights to improve networks and connected experiences.
Ookla® has formed a strategic partnership with BigPanda, a leading provider of agentic IT operations solutions, integrating Downdetector®’s real-time outage intelligence into BigPanda AI Incident Assistant. This partnership extends visibility beyond traditional internal monitoring, allowing IT teams to detect disruptions in external cloud platforms, SaaS providers, and ISPs that standard tools often miss.
The combination of Downdetector’s crowdsourced signals and BigPanda’s AI-powered investigation helps organizations understand whether an issue originates within internal systems or stems from a provider-side outage. Faster clarity leads to quicker root-cause identification, fewer unnecessary bridge calls, and more confident incident resolution.
“Our internal dashboards looked green, but the external signals told a different story,” said an engineering leader at a major global gaming studio. “Downdetector’s data triggered the investigation that helped us catch the issue before it escalated. Without that outside-in visibility, we would have been blind.”
Enterprise IT teams gain several advantages from the combined capabilities of BigPanda and Downdetector:
Avoid unnecessary bridge calls by ruling out internal code or infrastructure issues early
Reduce Mean Time to Innocence when an outage originates with a third-party provider
Accelerate root-cause analysis by surfacing provider-side factors at the start of an investigation
Communicate proactively with end users when the source of instability is a third-party outage
The integrated solution is available immediately for enterprises using BigPanda AI Incident Assistant with a Downdetector license.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Dave Andersen is a Marketing Program Manager at Ookla, where he creates enterprise and consumer content across Ookla’s brands. Dave got his start in the telco space in 2012, producing content for RootMetrics. Dave has a bachelors in marketing from Washington State University and studied creative writing in Oklahoma State’s MFA program.
In 2025, digital services proved both indispensable and fragile. This year’s largest outages were defined by platform-level disruptions, particularly across video, gaming, and communication platforms, that impacted millions of users. However, given how many individual platforms rely on the same few cloud providers and core systems, the role of centralized infrastructure also played a key role, demonstrating how a single point of failure can still cause disruption to cascade across multiple services simultaneously.
We used Downdetector® data from 2025 to analyze millions of user reports and identify the largest website and service outages of the year.
The World’s Biggest Outages of 2025
2025 saw a combination of major outages across gaming, streaming, and social media services, but none were more impactful than the cloud services outages that affected companies across the globe. These large-scale incidents underscored how failures in core infrastructure can ripple outward to millions of users. Here is a look at the largest global outages of 2025, according to Downdetector data.
AWS (Oct 20, 2025): The largest global incident of 2025 was the result of an AWS outage that received over 17 million Downdetector reports across Amazon and all other impacted services. This outage lasted over 15 hours and was traced to an issue with the automated DNS management system for DynamoDB in the US-EAST-1 region. This single point of failure caused widespread disruption across dependent platforms like Snapchat, Netflix, and various e-commerce sites.
PlayStation Network (Feb 7, 2025): The second largest global outage stemmed from the gaming sector, with over 3.9 million reports to the PlayStation Network Downdetector page. This network-wide disruption affected users for over 24 hours, locking out players from major titles like Call of Duty and Fortnite. Downdetector’s Incident Attribution analysis concluded the cause was internal to PSN, with no major cloud or ISP involvement.
Cloudflare (Nov 18, 2025): The world’s third-largest outage, registering over 3.3 million reports across all impacted services, was due to a global disruption within the core cloud infrastructure that lasted for nearly five hours. This massive incident affected countless websites, applications, and APIs that rely on Cloudflare’s services. The sheer scale and duration of user-reported issues highlighted the global dependence on centralized cloud infrastructure.
Biggest Outages in Each Region
Note: Global outage data is based on total reports across all impacted services while regional outage data is based on data for individual services.
United States and Canada
United States and Canada experienced the highest concentration of high-impact outages, with the top three all surpassing over 1 million reports.
PlayStation Network (Feb 7, 2025): Topped the chart with 1.6 million reports.
YouTube (Oct 15, 2025): Recorded 1.5 million reports during its global streaming issue.
AWS (Oct 20, 2025): The cloud outage drove 1.2 million reports to the status page.
Snapchat (Oct 20, 2025): With 944,675 reports, the social media app was a major casualty of the AWS incident.
Starlink (Jul 24, 2025): The satellite internet service saw a significant spike with 583,989 reports.
Verizon (Aug 30, 2025): A major telecommunications disruption at Verizon registered 515,923 reports, highlighting the continued vulnerability of connectivity services.
Europe (EU)
Europe’s outages were a mix of gaming, social, and major telecommunications disruptions.
PlayStation Network (Feb 7, 2025): The gaming platform’s global issue topped the EU list with 1.7 million reports.
Snapchat (Oct 20, 2025): This social media service saw the second-highest outage activity in the region with 989,559 reports submitted by users.
Vodafone (Oct 13, 2025): A UK-wide internet outage for this major telecommunications company generated 833,211 reports. The problem, attributed to a non-malicious software issue with a vendor partner, affected broadband, 4G, and 5G services.
WhatsApp (Feb 28, 2025): The messaging platform caused significant disruption for its users with 621,763 reports.
Spotify (Apr 16, 2025): The music streaming service’s outage recorded 468,334 reports, making it a major non-video streaming event.
Odido (June 15 + June 25, 2025): Within 10 days, the Netherlands telecommunications provider experienced two separate outages that totaled 357,685 reports (June 15th) and 382,003 reports (June 25th).
Asia Pacific (APAC)
Social media and cloud services dominated the largest outages in the Asia Pacific region.
X (Twitter) (Mar 10, 2025): X topped the list with 645,395 reports, demonstrating the service’s critical role in the region.
Snapchat (Oct 20, 2025): The social media app had the second-largest outage, with 399,108 reports.
YouTube (Oct 15, 2025): The global streaming issue that hit YouTube was felt acutely in the APAC region, registering 245,087 reports.
AWS (Oct 20, 2025): The cloud service failure drove 175,380 reports, with another AWS-related incident on April 15 adding 106,667 reports.
Latin America (LATAM)
Latin America’s largest outages featured global streaming and cloud failures, alongside significant regional financial and telecom disruptions.
YouTube (Oct 15, 2025): The streaming platform’s outage in October led the region with 183,672 reports.
AWS (Oct 20, 2025): The cloud services outage was the second largest in the region, recording 164,011 reports.
WhatsApp (Feb 28, 2025): The messaging platform saw 87,265 reports during a disruption in late February and then just two months later it experienced another outage that generated 57,095 reports.
Banco Itaú (Oct 6, 2025): This major banking platform’s outage registered 73,745 reports, highlighting a serious disruption in the banking and finance vertical.
Middle East and Africa (MEA)
The largest outages in the Middle East and Africa featured significant disruptions from key regional telecommunications providers alongside major global cloud and social media services.
Du (Feb 8, 2025): This telecommunications provider experienced a major disruption in February, recording 28,444 reports.
Cloudflare (Nov 18, 2025): The cloud service provider saw 28,016 reports in MEA during the global outage.
Snapchat (Oct 20, 2025): The social media platform registered 26,392 reports during a service disruption in October.
Conclusion
Downdetector is your source for information about service disruptions, monitoring real-time performance for thousands of popular web services globally. Businesses looking for early alerting on service issues, deeper competitive intelligence, and the ability to correlate an issue to an upstream or downstream provider may find Downdetector Explorer™, the enterprise version of Downdetector, a key resource.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Perry Haghighi is a Product Marketing Specialist supporting Ookla’s product lines, with a primary focus on Downdetector. With a degree in Business from UC San Diego and experience in both the telecommunication and entertainment industries, Perry’s expertise lies in understanding the nuances of strategic decisions and their impact on the end user.
A major service disruption involving Cloudflare last week underscored the systemic concentration risk present in today’s internet ecosystem, where so much of the world’s internet traffic depends on a small number of core providers. With over 3.3 million Downdetector user reports across all impacted services globally, the event demonstrated the wide-ranging and cascading impact that foundational infrastructure failures have on countless dependent online services.
Downdetector Reports Highlight Global Impact of Cloudflare Outage
The Cloudflare disruption on November 18, 2025, was not a simple capacity overload, but a systemic failure of the global control plane. Preliminary analysis indicates that a configuration update intended to optimize routing across the Cloudflare backbone inadvertently triggered a “thundering herd” scenario, causing edge locations to reject valid traffic.
As shown in the timeline below, the issue began at 11:00 AM UTC when the erroneous config propagated to the Europe and North America regions simultaneously. Because Cloudflare acts as the “immune system” and content delivery layer for a significant portion of the modern web, this single point of failure instantly decoupled backend infrastructure (AWS/Google) from end-users, affecting services ranging from low-latency gaming (League of Legends) to real-time AI inference (OpenAI).
The significant blast radius meant that the incident triggered a massive surge in user-reported problems. Downdetector amassed over 3.3 million global user reports across impacted services over the course of the outage. The graphic below offers a timeline of how the reports started to appear on Downdetector:
Downstream Impact: Services Most Affected by Cloudflare Outage
The primary impact was felt by services that rely on Cloudflare’s infrastructure. Besides just Cloudflare, we saw a surge in reports for a number of impacted services. Here is a look at the services that received the most reports during this time:
The impact spanned multiple critical verticals, including Streaming, Gaming, and Cloud/SaaS providers.
Global Outage Volume by Region
In addition to impacting individual services, we were able to track the global footprint of the outage by monitoring reports by country. The United States received the most reports during this time with over 150K reports on Cloudflare alone.
The ability to quickly see a geographic heatmap of problem reports is a key feature in the Downdetector Explorer dashboard, helping teams quickly see if an issue is regional or global.
A Succession of Major Outages is Stimulating Deeper Policymaker Oversight
This outage lands in the middle of a wider policy shift that treats large cloud and internet infrastructure providers as potential sources of systemic risk rather than ordinary vendors. In the EU, regulators have just published the first list of critical ICT third-party providers under the new Digital Operational Resilience Act (DORA), bringing hyperscale cloud, data centre and network providers into a dedicated oversight regime that explicitly targets concentration risk, while the UK is rolling out a parallel Critical Third Parties framework for services whose disruption could threaten financial stability.
Coming so soon after a major AWS outage and other large-scale incidents, the Cloudflare event is likely to be used as further evidence that dependence on a small number of core cloud and edge platforms is now a live concern for boards, regulators and policymakers, and that organizations need much better mapping, monitoring and stress-testing of their third-party digital dependencies.
For companies operating in these complex environments, understanding the true scope and source of a disruption is vital. Downdetector Explorer allows companies to quickly monitor both their own services and the third-party dependencies (like cloud hosting providers) to understand when external issues affect their customer experience.
Ready to turn user reports into actionable intelligence? Learn how you can leverage Downdetector to be better prepared for outages by visiting downdetector.com/for-business.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Ookla® is a global leader in connectivity intelligence that provides consumers, businesses, and other organizations with data-driven insights to improve networks and connected experiences.
Airline websites saw fifty times the average number of user reports on July 19, with Delta Airlines and Ryanair (a low-cost airline in Europe), having the largest number of reports in this sector, according to Downdetector.com.
A routine software update performed by cybersecurity firm CrowdStrike on July 19 caused what some believe to be the largest tech outage in IT history. Microsoft reported that the outage impacted around 8.5 million Microsoft Windows devices causing the devices to display the blue screen of death.
The outage resulted in major airlines being forced to ground their flights, TV news stations going off the air, hospitals canceling medical procedures, and banks being unable to transfer customers’ funds.
Downdetector by Ookla, which monitors real-time performance for thousands of popular web services globally, had a front row seat to the July 19 outage. Nearly 5 million reports were made to Downdetector.com on the status of different websites, which was more than three times the average number of users that typically visit the Downdetector site every day.
All major sectors of the economy see spike in outage reports
Downdetector reported surges in outage reports across a variety of sectors, from emergency services, which saw the largest increase over its daily average, at 68x, to airlines, retail, banking, and even dating services.
Not surprisingly, Microsoft bore the brunt of user reported outages. Microsoft witnessed a 42x increase over its daily average, while Microsoft 365, its cloud-based productivity suite, saw user reports increase 18x. Microsoft Azure was also impacted, with user reported outages up 21x.
Beyond software providers, transport, airlines, ride sharing and even e-commerce and delivery services saw large spikes in outage reports. Tesla saw an increase of 12x over its daily average, while user reported outages for Uber were up 57x, and Uber Eats experienced a 41x increase. Amazon witnessed a 14x increase in outage reports, while DHL and Fedex saw 6x and 4x increases respectively.
Verticals Impacted by CrowdStrike IT Outage
Increase in Outage Reports | Downdetector® | July 2024
Airline sites hit with 50% rise in reports
As was widely reported in the news, the airline industry was significantly impacted by the Crowdstrike-induced outage. OAG, a provider of digital flight information, reported that the world’s 20 largest airlines canceled nearly 10,000 flights between July 19 and July 21.
Delta Airlines was by far the most impacted of the large global airlines, having canceled 5,300 flights since the outage started. The airline is now under federal investigation for how it’s handling the delays and cancellations.
Not surprisingly, Downdetector’s data on the various airline websites shows that the airline category of websites experienced more than 50 times the average number of user reports on July 19, with Delta Airlines and Ryanair (a low-cost airline covering Europe), leading this sector. In fact, Delta alone experienced a 92x increase in user reports on July 19 compared to its typical daily average and United Airlines saw a 57x increase. Delta was still experiencing more than 6x the average daily number of user reports four days after the outage on July 23.
Airlines Impacted by CrowdStrike IT Outage
Number of Outage Reports | Downdetector® | July 2024
Digital banks and financial companies also struggled to serve their customers during the outage. Visa received more than 64,000 user reports on July 19 compared to its typical daily average of just 1,500 and online bank TDBank also saw its user reports increase to more than 56,000 on the 19th compared to its typical daily average of 240 reports.
Although most company websites have rebounded from the Crowdstrike debacle, the outage showcased just how vulnerable today’s websites are to software glitches and updates and how important tools like Downdetector.com are to providing real-time analysis.
Downdetector.com leverages more than 25 million monthly reports from individual users to make sure you have reliable information about the status of services that are important to you. For more, please read this blog post.
Editor’s Note: This article was updated August 6 from 5 million users to 5 million reports to better reflect how Downdetector tracks the number of outage reports submitted.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Sue Marek is Ookla’s editorial director and part of the company’s analyst team. She oversees the company’s thought leadership and editorial content. Sue is a journalist with more than 30 years of experience covering the telecom industry and her work has appeared in Fierce Network, Light Reading, and SDxCentral. She is a frequent speaker at industry events and has moderated panels at Mobile World Las Vegas, Connect(x), the Consumer Electronics Show, the Competitive Carriers’ Show and 5G North America. Sue has a B.S. in journalism from the University of Colorado.
Our reliance on technology is so total that for many it feels like the world is ending when a popular site or service on the internet is inaccessible, and 2024 saw many outages that reminded us how much one such interruption can disrupt the daily lives of millions. We analyzed Downdetector® data from Q1-Q3 2024 to see where that pain of disconnection was felt most acutely. Read on to revisit the largest outages of 2024 at a global level and sorted by region.
Note that while some companies experienced more than one large outage during this time period, we’ve listed only the largest incident per company in each chart.
The world’s biggest outages this year
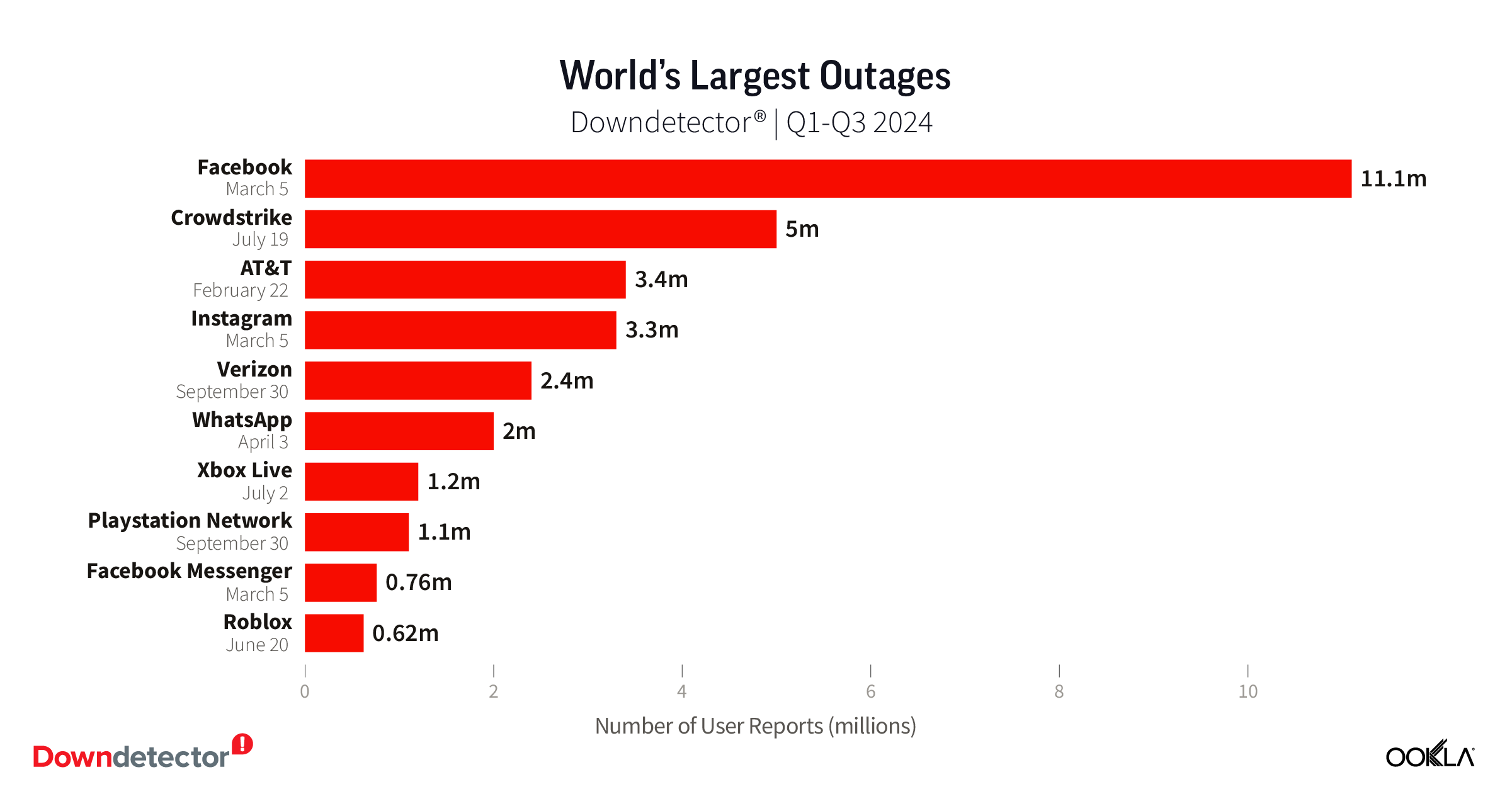
Users of social media sites, internet providers, and gaming sites and services suffered the most disruptions this year according to Downdetector data on the world’s biggest outages. Facebook had the largest outage on our list. On March 5, over 11.1 million people across the world reported issues with the popular social media site.
The second largest global outage may be the most memorable. While CrowdStrike is not a service most people think of, we saw nearly 5 million reports to services that rely on it (or rely on Microsoft which relies on Crowdstrike), including emergency services, airlines, and ride sharing apps when a routine software update went bad on July 19.
AT&T suffered the third largest outage in the world, according to Downdetector data, when an equipment configuration error caused customers across the entire United States to lose network access for over 12 hours.
Biggest outages in each region
Asia Pacific region hit by global outages
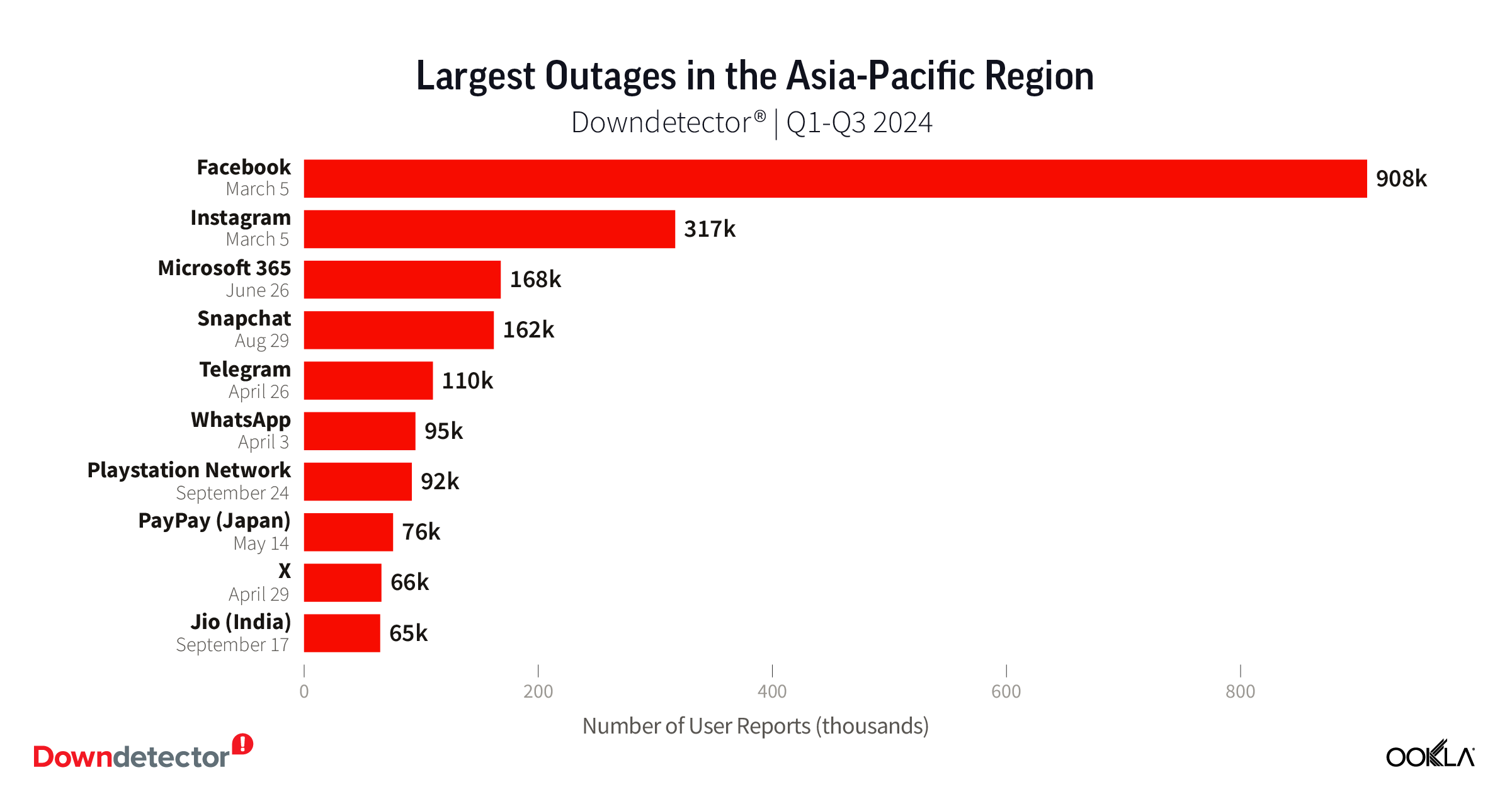
The March 5 Facebook outage also topped the list of outages in the Asia-Pacific region, instigating over 908k user reports to Downdetector and taking Instagram down with it as the second largest outage. The third largest outage happened on June 26 when over 168k Microsoft 365 users in the Asia-Pacific region reported service disruptions on the service. Japan was especially hard hit with over 139k user reports from that country alone.
People in the Asia-Pacific region were also affected by local outages, with over 76k users reporting issues with Japanese payment system PayPay in May, and 65k users in India reported issues with Jio during a September service disruption.
Europe struggles with social media sites
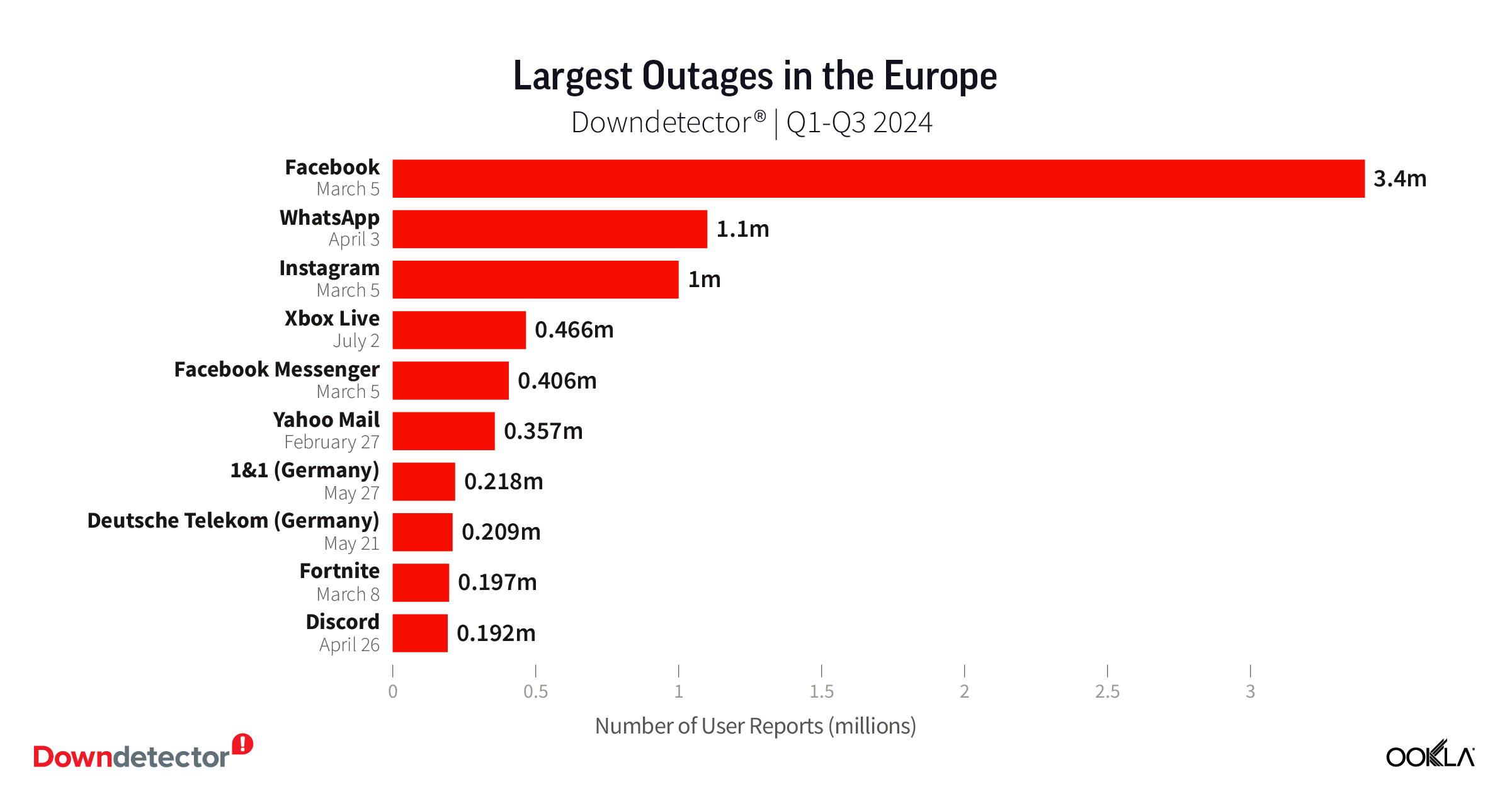
Social media sites were the main source of disconnection in Europe according to data from Downdetector. Over 3.4 million European users reported issues with Facebook during the March 5 outage, making that the largest outage in Europe during Q1-Q3 2024. WhatsApp users suffered the second largest outage in Europe with over 1.1 million people reporting issues during an outage in early April.
Two German companies also showed up on our list of largest outages in Europe with over 218k reports of issues with 1&1 and over 209k reports of issues with Deutsche Telekom when the two companies experienced service disruptions almost a week apart in late May.
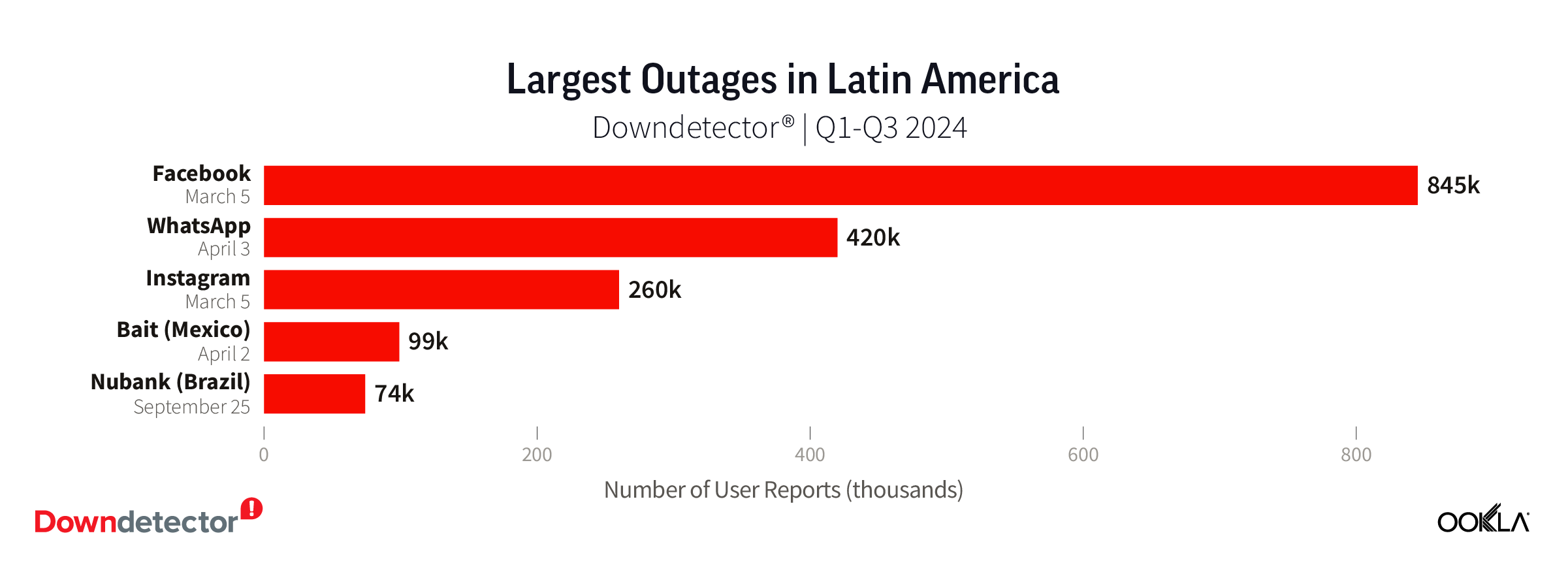
Latin America feels pain from global social outages
Latin America’s top three outages mirrored those in Europe with social media sites causing the most pain for users according to data from Downdetector. The March 5 Facebook outage was felt profoundly with almost 850k user reports on Downdetector in Latin America for issues related to Facebook and over 260k related to Instagram. WhatsApp had the second largest outage in the region with almost 420k user reports during the two hours the service was down on April 3.
Bait, a Mexican Mobile Virtual Network Operator (MVNO) owned by Walmart, suffered an outage on April 2 where almost 99k users reported issues to Downdetector. And on September 24, over 74k users reported issues with Brazilian fintech bank Nubank.
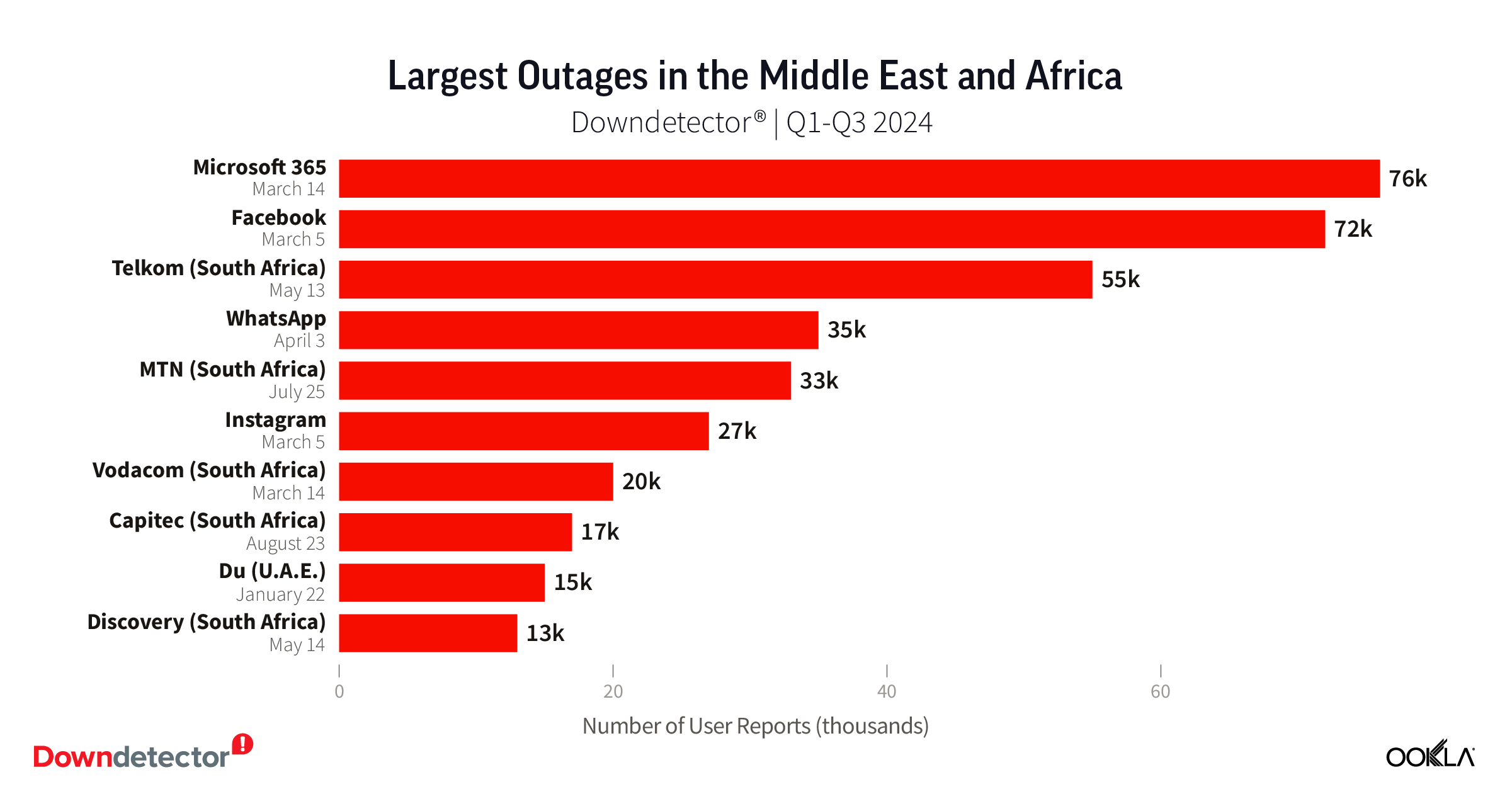
Middle East and Africa experience mix of local and global outages
Outage patterns in the Middle East and Africa differed from those in other regions with users reporting about as many issues with local sites and services as global ones. The two largest outages, Microsoft 365 on March 14 and Facebook on March 5, were part of global events.
The third largest outage in the region was with South African telecommunications provider Telkom. Almost 55k users across Africa reported issues to Downdetector when Telkom experienced an outage on May 13. MTN, Vodacom, and du are other telecom providers that made our list of top outages in the Middle East and Africa during Q1-Q3 2024.
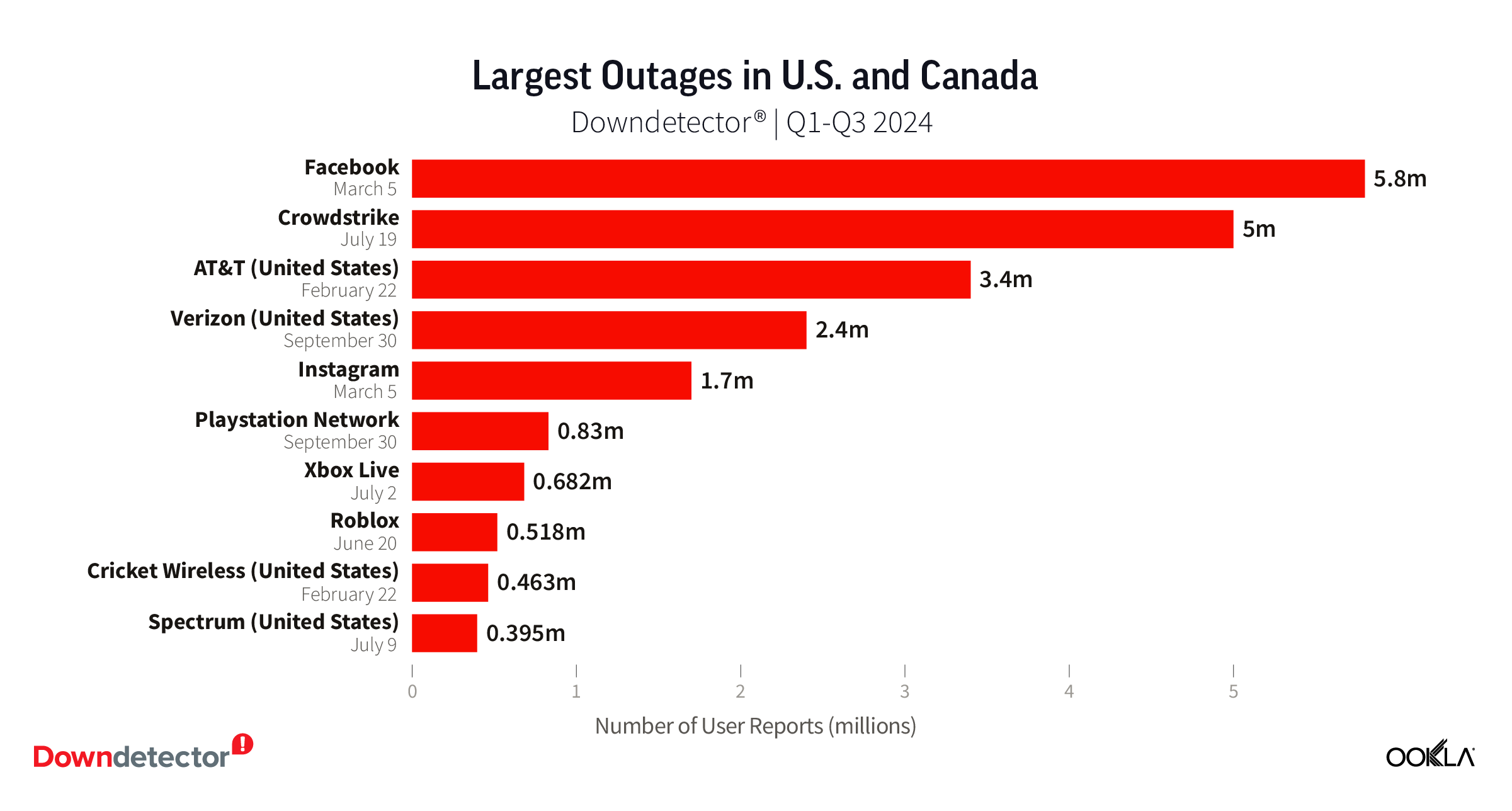
United States and Canada
As we saw with much of the rest of the world, Facebook topped the list of outages in the U.S. according to Downdetector with over 5.8 million users reporting issues with the service during its outage on March 5. The Crowdstrike and AT&T outages also hit the U.S. hard with almost 5 million and over 3.4 million user reports, respectively. Gaming sites and services and telecom providers filled out the rest of the list in the U.S.
Downdetector is your source for information about service disruptions, monitoring real-time performance for thousands of popular web services globally. Find Downdetector on the web or in the free Speedtest app for Android or iOS. We’ve recently introduced push notifications so you can learn about outages as soon as they happen. Businesses looking for early alerting on service issues may be interested in Downdetector ExplorerTM.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
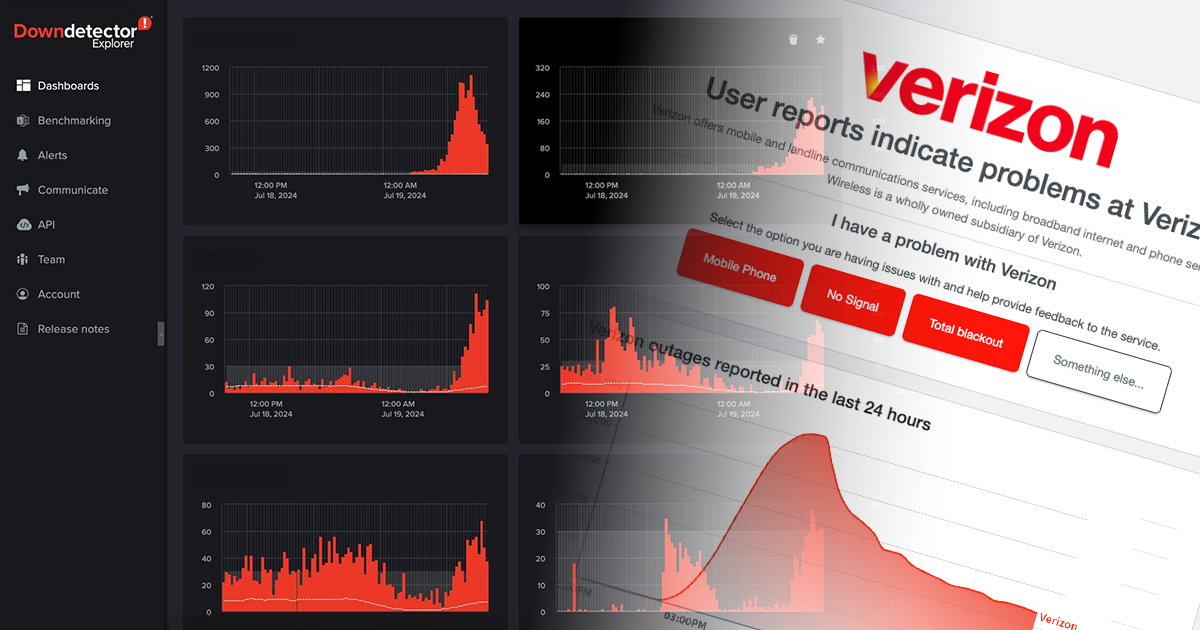
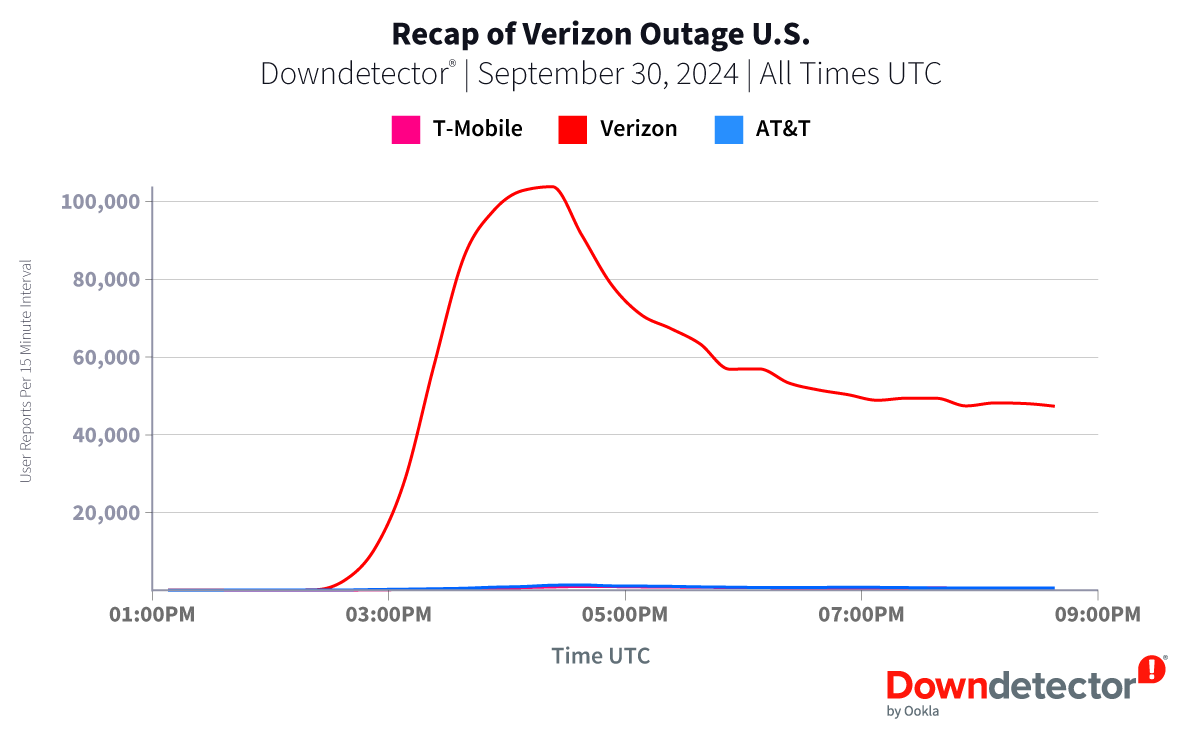
On September 30th, a significant outage impacted Verizon services across the U.S., with reports pouring into Downdetector throughout the day. Users reported a range of issues, including phones stuck in SOS mode and the inability to make or receive calls and texts, leading to over 1.7 million reports in Downdetector.
The first alerts of this issue came in as early as 9:30 AM EDT. For businesses, receiving timely notifications like these is crucial; early awareness enables proactive resolution of potential issues before they escalate into major disruptions.
Here’s a summary of how user reports flooded into Downdetector, providing key real-time insights into the outage as it unfolded.
9:30 AM EDT — Initial Reports Appear in Downdetector
Reports of a Verizon outage began surfacing on Downdetector, as subscribers noticed their phones were stuck in SOS mode. By 9:30 AM approximately 1,000 users had reported issues. While this situation had yet to be acknowledged by the press or Verizon, Downdetector Explorer customers received early warning signs of a potential service disruption.
11:23 AM EDT — Outage Number Peaks
Downdetector monitors and reports numbers in 15 minute increments. Over 100,000 incidents were submitted between 11:15-11:30 AM, bringing the total number of reports to over 400,000 at this point. Verizon would continue to receive reports throughout the course of the entire day as users were continuously impacted.
Despite Verizon being the source of the service disruption, customers of AT&T and T-Mobile also began reporting issues. These reports were likely a result of AT&T and T-Mobile users attempting to contact Verizon subscribers rather than an issue with AT&T and T-Mobile’s services. In order to ensure all reports were accurately captured, Downdetector displayed banners reporting that reports of service outages for AT&T and T-Mobile may be related to issues at Verizon.
11:48 AM EDT — Verizon Acknowledges the Outage
More than two hours after the first reports appeared, Verizon confirmed the outage on X, assuring users that they were aware of the situation and working to resolve it.
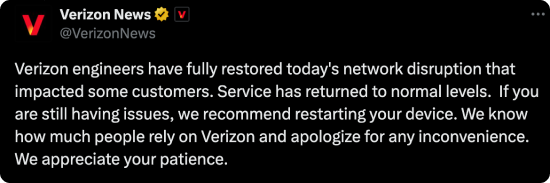
7:18 PM EDT — Resolution Announced
After nearly 10 hours and over 1.7 million reports, Verizon announced that the outage had been resolved, though as of the time of publication, there has not been an official statement on what caused the outage.
Downdetector has proven to be an invaluable tool for real-time outage reporting, identifying issues faster than official communications from service providers. If you’re interested in learning how Downdetector can help you identify and prevent disruptions from becoming major outages reach out to us.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Perry Haghighi is a Product Marketing Specialist supporting Ookla’s product lines, with a primary focus on Downdetector. With a degree in Business from UC San Diego and experience in both the telecommunication and entertainment industries, Perry’s expertise lies in understanding the nuances of strategic decisions and their impact on the end user.
On December 11th, 2024, a significant outage affected Meta services, disrupting Facebook, WhatsApp, Instagram, and Messenger users worldwide. Reports of the outage flooded into Downdetector, with the platform providing real-time insights as the event unfolded. The scale of the disruption underscored the critical role Downdetector plays in tracking and identifying service issues for businesses and consumers alike.
Here’s a timeline of how the outage progressed, based on data captured in Downdetector.
9:45 AM PST — Initial Reports Appear in Downdetector
Reports of a Meta service disruption began to surface, with users globally reporting issues on Facebook, WhatsApp, and Instagram. Users received error messages when attempting to access the services.
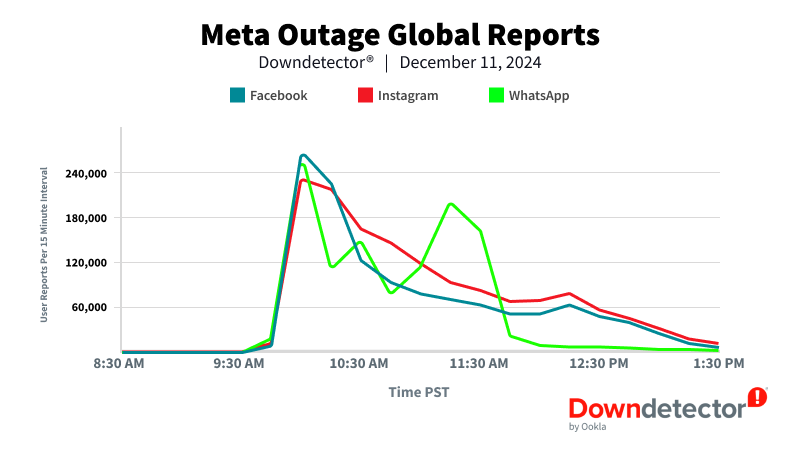
10:00-10:15 AM PST — Outage Number Peaks
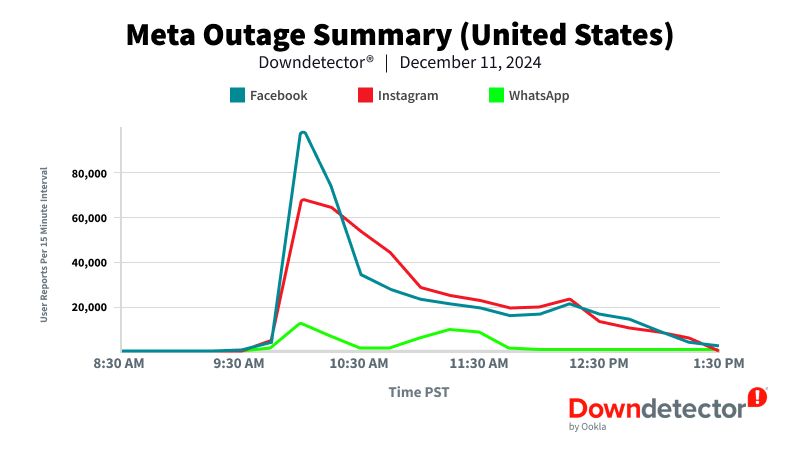
With the outage peaking across the world during this time, using Downdetector data we compared the reporting numbers on Meta’s services across the Americas. In the United States, Facebook reported the highest number of disruptions, with nearly 100,000 user-submitted incidents during this 15 minute window.
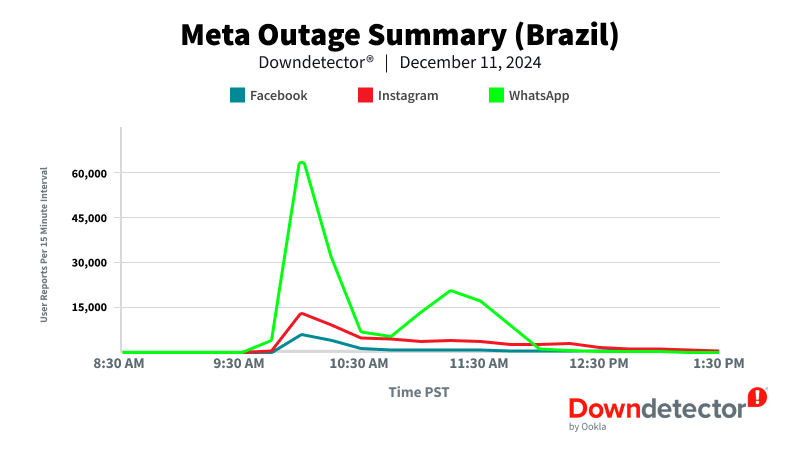
Meanwhile, in Brazil, WhatsApp saw the most significant impact, with 66,000 reports in the same timeframe.
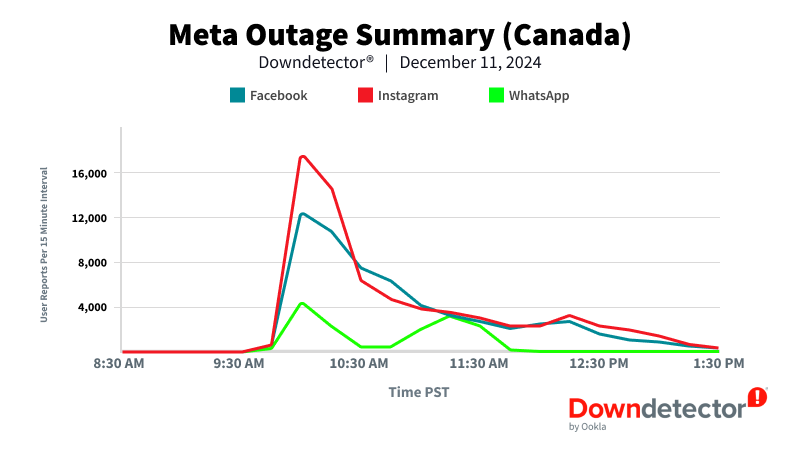
In Canada, Instagram peaked with the most reports with 17,000 reports during this time.
These figures highlight the global reach of the outage and shows how the popularity of Meta’s services vary by region, with different platforms experiencing peak number of reports in different countries.
10:48 AM PST — Meta Acknowledges the Outage
Over an hour after Downdetector users were first notified of a potential disruption, Meta addressed the issue on X, assuring users that they were aware of the outage and were actively working to resolve it.
11:30 AM PST — Reports Exceed 3 Million Globally
As Meta worked on resolving the issue, users were still impacted and reports continued to flood into Downdetector. As of 11:30 AM PST the total number of reports exceeded 3 million globally.
12:00 PM PST — Speedtest Counts Peak
During the outage, many users turned to Speedtest to troubleshoot their internet connections, unsure if the issue stemmed from their provider or Meta’s services. As a result, Speedtest Intelligence® recorded a sharp increase in test counts throughout the outage. Starting at 10:00 AM PST, test activity began to rise, peaking at over 110,000 tests on fixed providers in Brazil alone by 12:00 PM PST.
This surge demonstrates a clear correlation between Speedtest and Downdetector, as users rely on both platforms as essential tools for diagnosing connectivity and service issues.
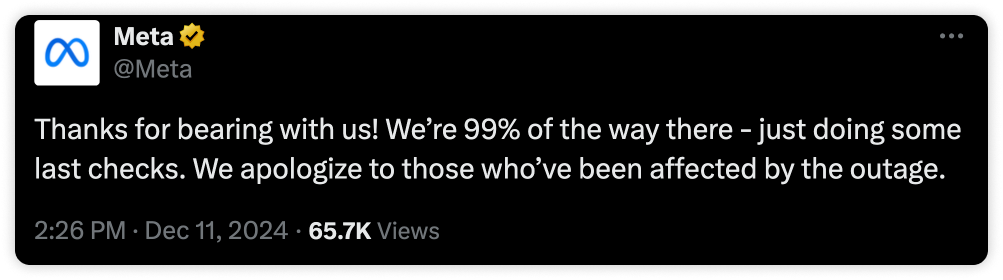
2:26 PM PST — Resolution Announced
After 5 hours and nearly 4 million reports across Facebook, WhatsApp, and Instagram globally, Meta announced that 99% of the outage had been resolved, with services returning to normal. As of this time, the exact cause of the disruption has not been disclosed.
Downdetector has proven to be an invaluable tool for real-time outage reporting, identifying issues faster than official communications from service providers. If you’re interested in learning how Downdetector can help you identify and prevent disruptions from becoming major outages contact us here.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Perry Haghighi is a Product Marketing Specialist supporting Ookla’s product lines, with a primary focus on Downdetector. With a degree in Business from UC San Diego and experience in both the telecommunication and entertainment industries, Perry’s expertise lies in understanding the nuances of strategic decisions and their impact on the end user.
Single points of logical failure topple even the most hardened cloud infrastructure, crippling today’s highly concentrated internet ecosystem.
Editor’s note: This article was updated on October 22 following a 48-hour review period related to the AWS outage, reflecting an upward revision of the total Downdetector user report volume from 16M+ to 17M+.
An Amazon Web Services (AWS) disruption on October 20, 2025, centered on its “US‑EAST‑1” cloud region triggered a wave of failures across consumer apps, finance, government portals and parts of Amazon’s own services. Downdetector® recorded 17M+ user reports (+970% increase on average daily baseline) and disruptions at over 3,500 companies across more than 60 countries, placing this among the largest internet outages on record for Downdetector.
Key Takeaways:
This outage had exceptional global reach and deep cross-sector impact. Downdetector captured 17M+ outage reports globally across 60+ countries, with the US (>6.3M) and UK (>1.5M) leading outage volumes. Services with the most reports included Snapchat (~3M), Roblox (~716k) and Amazon retail (~698k), and spanned everything from banking to gaming services.
Rapid cascade and phased restoration. Thefirst outage spikes appeared around 06:50–07:00 UTC. AWS identified DNS resolution issues affecting DynamoDB endpoints in US‑EAST‑1 and reported mitigation by 09:24 UTC, with full normalization later in the day as downstream services cleared backlogs on a phased basis. Outage reports underwent a second surge in the late afternoon (UTC) as U.S. users awoke to disruptions.
Not a one-off event. The outage echoes recent systemic failures, including Meta’s 2021 BGP/DNS issue, Fastly and Akamai CDN outages, the 2024 CrowdStrike update failure, the 2025 Cloudflare-AWS interconnect incident and the recent Google Cloud outage, revealing single points of failure in shared infrastructure.
Wake-up call for critical infrastructure. The lesson is concentration risk (or overreliance on a single point of failure). The service layer is now tightly coupled to a handful of cloud regions and managed services. The way forward is not zero failure but contained failure, achieved through multi-region designs, dependency diversity, and disciplined incident readiness, with regulatory oversight that moves toward treating the cloud as systemic components of national and economic resilience.
The “blast radius” reached far beyond Virginia, where the affected AWS US-EAST-1 is located
Downdetector captured 17M+ global user reports from 00:00 UTC on Oct 20 to 09:15 UTC on Oct 21, with 3,500+ of the companies Downdetector tracks seeing elevated disruptions and 19 still ongoing the following morning. Country volumes were led by the US (6.3M+), UK (1.5M+), Germany (774k), Netherlands (737k) and Brazil (589k).
The heaviest‑hit services by report count included Snapchat (~3M), AWS itself (~2.5M), Roblox (~716k), Amazon retail (~698k), Reddit (~397k), Ring (~357k) and Instructure (~265k). The UK alone generated more than 1.5M reports, far exceeding a typical day’s ~1M global baseline across all markets, highlighting both the unique intensity and breadth of this event.
Analysis of sectoral outcomes in Downdetector reports reveal impacts spanned social/gaming (Snapchat, Fortnite, Roblox), finance (e.g., UK banks like Lloyds and Halifax), public services (HMRC), smart home (Ring, Alexa), and education/work tools (Instructure, Zoom). Outage peaks and troughs varied by time zone, with European volumes rising first as workplaces came online and a second lift as North America woke up later in the day:
~06:49 UTC (Oct 20): First user reports and AWS status signals line up. Downdetector registered sharp spikes shortly after 06:56 UTC on US‑EAST‑1‑linked services. Within two hours of outage commencement, over 4M outage reports were submitted.
~09:24 UTC: AWS says the core fault, involving DNS resolution issues for regional DynamoDB endpoints in US‑EAST‑1, was mitigated.
Remainder of the day: Dependent services recovered at different speeds as retries, queues and caches drained. Major outlets tracked staged restoration through the afternoon and evening local time, with Downdetector reports surging past 6M in the U.S. as users came online.
This pattern, reflecting a relatively short underlying cloud incident based on a common denominator (AWS US-EAST-1 concentration) with longer downstream normalization, is customary when a foundational component (in this case DNS to a regional database endpoint) sits behind many higher‑level services and microservices.
Regional concentration and tight coupling of managed services amplified outage impact
The affected US‑EAST‑1 is AWS’s oldest and most heavily used hub. Regional concentration means even global apps often anchor identity, state or metadata flows there. When a regional dependency fails as was the case in this event, impacts propagate worldwide because many “global” stacks route through Virginia at some point.
Modern apps chain together managed services like storage, queues, and serverless functions. If DNS cannot reliably resolve a critical endpoint (for example, the DynamoDB API involved here), errors cascade through upstream APIs and cause visible failures in apps users do not associate with AWS. That is precisely what Downdetector recorded across Snapchat, Roblox, Signal, Ring, HMRC, and others.
Another complicating factor in this outage was authentication. Problems with DynamoDB also hit IAM (authentication), which handles sign in and permissions. Early on, some teams could not log in to the AWS console. Where teams cannot sign in to the tools that change settings, move traffic, or restart services, it is very difficult to apply fixes, so recovery slows even after core systems start to come back.
Even after the provider (AWS in this case) fully mitigated the issue, retries, timeouts and message backlogs took time to clear. Teams often throttle restarts to protect back ends, so user-visible recovery lags the provider’s green status. The afternoon and evening recovery curve observed in Downdetector reports, first in Europe and then in the U.S., matches this pattern.
Companies should plan for region failure and practise graceful slowdowns during outages
For companies dependent on these platforms, a practical response to an outage of this magnitude begins with designing for failure and assuming a whole cloud region can go down. This means not relying on a single region (e.g., US-EAST-1) for critical systems and instead running services across multiple regions (known as active-active) or keeping a lightweight standby (“pilot light”) that can be promoted quickly. For highly mission-critical services, the use of a multi-cloud setup can improve availability during provider-wide incidents, but this is not practical for many companies due to the costs of duplication and additional complexity.
Similarly, companies should plan for graceful slowdowns, not just total outages. This means using circuit breakers and feature flags to turn off non-essential features (like media uploads or recommendations) so that core flows such as sign-in, search, or checkout stay up. Practicing the act of “failing safely” is important, often achieved through running game days that simulate DNS, database, and authentication outages. Investing in measuring time to detect, time to fail over, and understanding how clear customer communications are is also important.
In real incidents like this, it is important that companies compare their own telemetry with public signals (e.g., Downdetector) to understand if the issue is provider-wide. When the facts are established, early communication with customers via status pages or in-app notifications is critical to reduce support load and protect trust.
Policymakers should treat cloud infrastructure as systemic components of national digital resilience
This outage again shows that cloud platforms are systemic infrastructure, characterized by a massive blast radius when a single point of logical failure emerges. It highlights the limitations of investing in enhancing physical resilience and redundancy alone (e.g., multi-day backup power on-site) if there is a fault elsewhere in the infrastructure stack on which everything else depends and from which failures cascade. Improving outcomes requires dismantling these single points of failure through diversification across each layer.
At a policy level, governments are starting to recognise this systemic risk and are beginning to adopt a more muscular approach to oversight. The EU’s flagship Digital Operational Resilience Act (DORA) introduces EU-level oversight of critical ICT third-party providers, while the UK’s Critical Third Parties regime does the same for finance.
Together, these policy developments aim to create a stronger toolkit, based on dependency mapping, stress tests, incident reporting discipline, and minimum post-event transparency, that will likely (and should) in time extend beyond financial services to other essential sectors (e.g., health, transport, and government). Importantly, proponents argue that adoption of these approaches would improve societal resilience without unduly micromanaging architectural choices.
For businesses, Downdetector provides access to dashboards that deliver early alerts, enable outage correlation, and allow for direct communication with users, ensuring a proactive approach to incident management. Learn how you can leverage Downdetector to be better prepared for outages, or reach out to schedule a demo.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Luke Kehoe leads Ookla’s research and thought leadership efforts in Europe.
An electronic engineering alumnus of University College Dublin, Luke has extensive experience collaborating with mobile operators, telecoms vendors, and government agencies in research and advisory roles across Europe. He has contributed to internationally recognised thought leadership publications in areas such as 5G, IoT, open RAN, and edge computing, working with prestigious organisations like the Telecom Infra Project and the World Economic Forum.
When you want to check your internet performance, you take a Speedtest®. If you can’t connect to a site, you check Downdetector®. Now, we’ve added a new Downdetector tab in the Speedtest app so you can do both in one location. This combines the internet’s most trusted app for testing connectivity with Downdetector’s real-time status information for over 12,000 apps, websites, and services across in 47 countries — with one tap. Using these free utilities, you can now diagnose whether your connection is in trouble or if there’s a larger service issue all in one place.
This is the same methodology we use for the Downdetector site you’ve come to trust. It’s simply in a more convenient location.
Check for online outages
Tap the “Status” tab at the bottom center of the Speedtest app to see a snapshot of the current status of the apps, websites, and services Downdetector monitors, tailored to show what’s most relevant in your country. Sites and services that are experiencing problems will appear at the top, giving you a quick view of whether the problem you’re experiencing is more widespread. Read more about how a few critical services can take down chunks of the internet here.
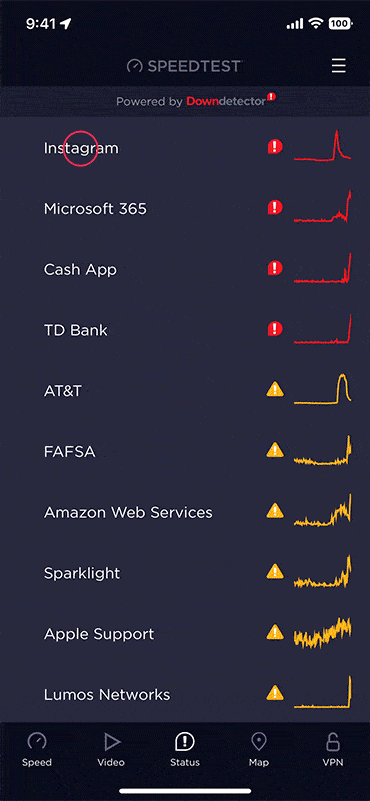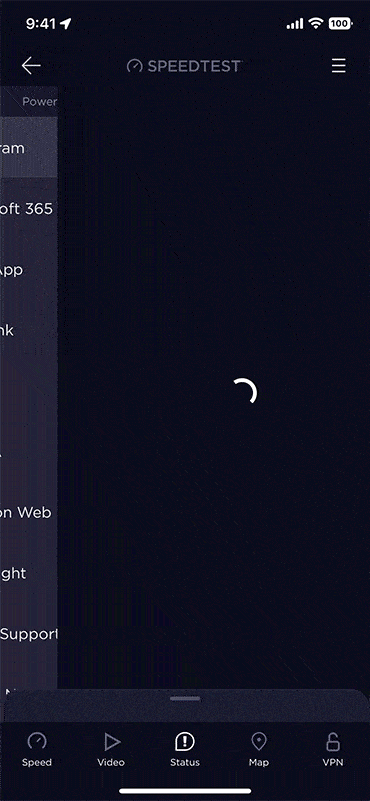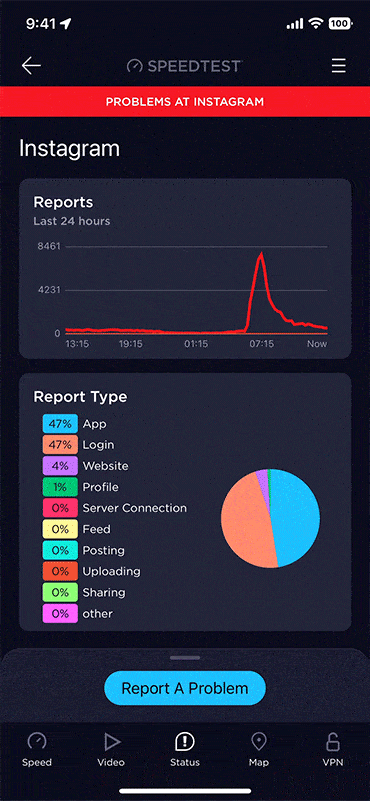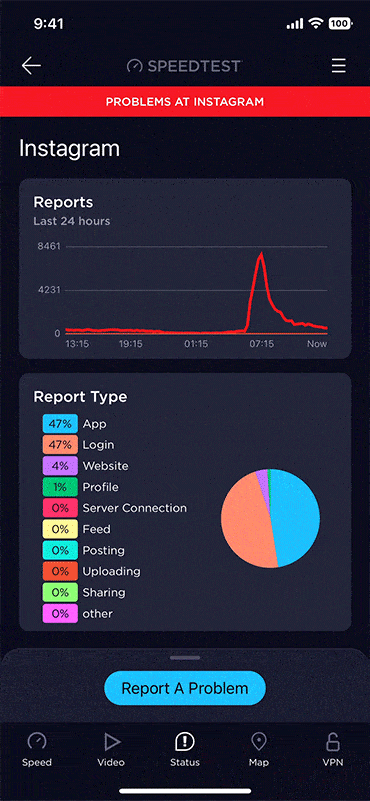
Check for details on a specific incident
Tap any site or service on the status page for a more detailed view of what’s going on. You’ll see a graph of incident reports over the last 24 hours as well as a chart of what types of issues users have reported. You can also tap on the blue button at the bottom of the page to submit your own report to Downdetector including information about your experience. This helps other users understand what they might also be experiencing.
Coming soon
This update is currently rolling out to Android and iOS devices worldwide. Update your Speedtest app if you don’t see the Downdetector tab. Soon we’ll also be adding in the ability to search for a specific site or service. Keep an eye out for this and other improvements as you troubleshoot your internet connectivity in the Speedtest app.
Download the Speedtest app for Android or iOS today to check out this new feature and let us know what you think on Twitter or Facebook.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
Ookla® is a global leader in connectivity intelligence that provides consumers, businesses, and other organizations with data-driven insights to improve networks and connected experiences.